 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen-Image-Bench: From Generation to Creation in Text-to-Image Evaluation
May 27, 2026Text-to-Image generation has evolved from basic image synthesis into a frequently used core capability in professional creative workflows, where simple text-image alignment can no longer satisfy users' pressing demands for faithful real-world reconstruction and genuine creative expression. Existing benchmarks, however, remain anchored in these foundational criteria and do not yet capture the nuanced capabilities that matter in authentic artistic practice, making it difficult to reliably distinguish state-of-the-art T2I models. To address the gap, we introduce Qwen-Image-Bench, a creator-centric benchmark co-designed with professional artists and grounded in real-world creation scenarios. Qwen-Image-Bench enriches conventional evaluation with two application-driven dimensions: Real-world Fidelity and Creative Generation. Drawing on the staged reasoning inherent in professional artistic workflows, we organize these five pillars into a top-down hierarchical taxonomy that further decomposes into 23 second-level sub-capabilities and 56 third-level verifiable rubrics. To ensure broad coverage, we curate 1000 stratified prompts with each prompt jointly exercising more than four fine-grained facets across multiple pillars. We train a unified judge model Q-Judger based on Qwen3.6-27B, supervised by 80 professional annotators from global art academies under blind labeling and triple-review protocols, that scores every image across all 56 verifiable facets, producing fine-grained, rubric-grounded, and fully attributable diagnostics rather than a single opaque score. Empirically, Qwen-Image-Bench reliably distinguishes leading T2I models, achieving the greatest separation on the two application-driven dimensions of Real-world Fidelity and Creative Generation where existing benchmarks provide little insight, while also providing a trustworthy optimization signal for production-level T2I development.
Qwen-Image-VAE-2.0 Technical Report
May 13, 2026We present Qwen-Image-VAE-2.0, a suite of high-compression Variational Autoencoders (VAEs) that achieve significant advances in both reconstruction fidelity and diffusability. To address the reconstruction bottlenecks of high compression, we adopt an improved architecture featuring Global Skip Connections (GSC) and expanded latent channels. Moreover, we scale training to billions of images and incorporate a synthetic rendering engine to improve performance in text-rich scenarios. To tackle the convergence challenges of high-dimensional latent space, we implement an enhanced semantic alignment strategy to make the latent space highly amenable to diffusion modeling. To optimize computational efficiency, we leverage an asymmetric and attention-free encoder-decoder backbone to minimize encoding overhead. We present a comprehensive evaluation of Qwen-Image-VAE-2.0 on public reconstruction benchmarks. To evaluate performance in text-rich scenarios, we propose OmniDoc-TokenBench, a new benchmark comprising a diverse collection of real-world documents coupled with specialized OCR-based evaluation metrics. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction performance, demonstrating exceptional capabilities in both general domains and text-rich scenarios at high compression ratio. Furthermore, downstream DiT experiments reveal our models possess superior diffusability, significantly accelerating convergence compared to existing high-compression baselines. These establish Qwen-Image-VAE-2.0 as a leading model with high compression, superior reconstruction, and exceptional diffusability.
Qwen-Image-2.0 Technical Report
May 11, 2026We present Qwen-Image-2.0, an omni-capable image generation foundation model that unifies high-fidelity generation and precise image editing within a single framework. Despite recent progress, existing models still struggle with ultra-long text rendering, multilingual typography, high-resolution photorealism, robust instruction following, and efficient deployment, especially in text-rich and compositionally complex scenarios. Qwen-Image-2.0 addresses these challenges by coupling Qwen3-VL as the condition encoder with a Multimodal Diffusion Transformer for joint condition-target modeling, supported by large-scale data curation and a customized multi-stage training pipeline. This enables strong multimodal understanding while preserving flexible generation and editing capabilities. The model supports instructions of up to 1K tokens for generating text-rich content such as slides, posters, infographics, and comics, while significantly improving multilingual text fidelity and typography. It also enhances photorealistic generation with richer details, more realistic textures, and coherent lighting, and follows complex prompts more reliably across diverse styles. Extensive human evaluations show that Qwen-Image-2.0 substantially outperforms previous Qwen-Image models in both generation and editing, marking a step toward more general, reliable, and practical image generation foundation models.
Quotient-Space Diffusion Models
Apr 23, 2026Diffusion-based generative models have reformed generative AI, and have enabled new capabilities in the science domain, for example, generating 3D structures of molecules. Due to the intrinsic problem structure of certain tasks, there is often a symmetry in the system, which identifies objects that can be converted by a group action as equivalent, hence the target distribution is essentially defined on the quotient space with respect to the group. In this work, we establish a formal framework for diffusion modeling on a general quotient space, and apply it to molecular structure generation which follows the special Euclidean group $\text{SE}(3)$ symmetry. The framework reduces the necessity of learning the component corresponding to the group action, hence simplifies learning difficulty over conventional group-equivariant diffusion models, and the sampler guarantees recovering the target distribution, while heuristic alignment strategies lack proper samplers. The arguments are empirically validated on structure generation for small molecules and proteins, indicating that the principled quotient-space diffusion model provides a new framework that outperforms previous symmetry treatments.
Luminark: Training-free, Probabilistically-Certified Watermarking for General Vision Generative Models
Jan 03, 2026In this paper, we introduce \emph{Luminark}, a training-free and probabilistically-certified watermarking method for general vision generative models. Our approach is built upon a novel watermark definition that leverages patch-level luminance statistics. Specifically, the service provider predefines a binary pattern together with corresponding patch-level thresholds. To detect a watermark in a given image, we evaluate whether the luminance of each patch surpasses its threshold and then verify whether the resulting binary pattern aligns with the target one. A simple statistical analysis demonstrates that the false positive rate of the proposed method can be effectively controlled, thereby ensuring certified detection. To enable seamless watermark injection across different paradigms, we leverage the widely adopted guidance technique as a plug-and-play mechanism and develop the \emph{watermark guidance}. This design enables Luminark to achieve generality across state-of-the-art generative models without compromising image quality. Empirically, we evaluate our approach on nine models spanning diffusion, autoregressive, and hybrid frameworks. Across all evaluations, Luminark consistently demonstrates high detection accuracy, strong robustness against common image transformations, and good performance on visual quality.
Diagnosing and Improving Diffusion Models by Estimating the Optimal Loss Value
Jun 16, 2025Diffusion models have achieved remarkable success in generative modeling. Despite more stable training, the loss of diffusion models is not indicative of absolute data-fitting quality, since its optimal value is typically not zero but unknown, leading to confusion between large optimal loss and insufficient model capacity. In this work, we advocate the need to estimate the optimal loss value for diagnosing and improving diffusion models. We first derive the optimal loss in closed form under a unified formulation of diffusion models, and develop effective estimators for it, including a stochastic variant scalable to large datasets with proper control of variance and bias. With this tool, we unlock the inherent metric for diagnosing the training quality of mainstream diffusion model variants, and develop a more performant training schedule based on the optimal loss. Moreover, using models with 120M to 1.5B parameters, we find that the power law is better demonstrated after subtracting the optimal loss from the actual training loss, suggesting a more principled setting for investigating the scaling law for diffusion models.
Bridging Geometric States via Geometric Diffusion Bridge
Oct 31, 2024



The accurate prediction of geometric state evolution in complex systems is critical for advancing scientific domains such as quantum chemistry and material modeling. Traditional experimental and computational methods face challenges in terms of environmental constraints and computational demands, while current deep learning approaches still fall short in terms of precision and generality. In this work, we introduce the Geometric Diffusion Bridge (GDB), a novel generative modeling framework that accurately bridges initial and target geometric states. GDB leverages a probabilistic approach to evolve geometric state distributions, employing an equivariant diffusion bridge derived by a modified version of Doob's $h$-transform for connecting geometric states. This tailored diffusion process is anchored by initial and target geometric states as fixed endpoints and governed by equivariant transition kernels. Moreover, trajectory data can be seamlessly leveraged in our GDB framework by using a chain of equivariant diffusion bridges, providing a more detailed and accurate characterization of evolution dynamics. Theoretically, we conduct a thorough examination to confirm our framework's ability to preserve joint distributions of geometric states and capability to completely model the underlying dynamics inducing trajectory distributions with negligible error. Experimental evaluations across various real-world scenarios show that GDB surpasses existing state-of-the-art approaches, opening up a new pathway for accurately bridging geometric states and tackling crucial scientific challenges with improved accuracy and applicability.
One Transformer Can Understand Both 2D & 3D Molecular Data
Oct 04, 2022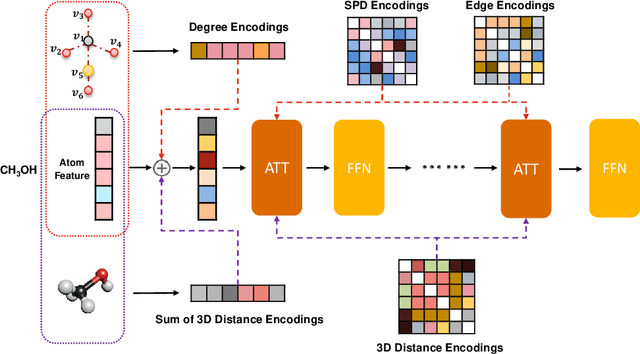
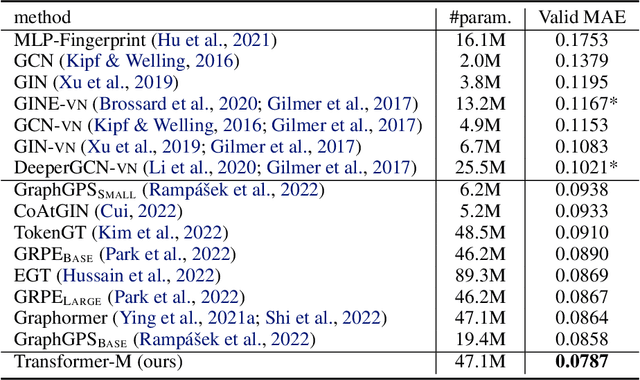
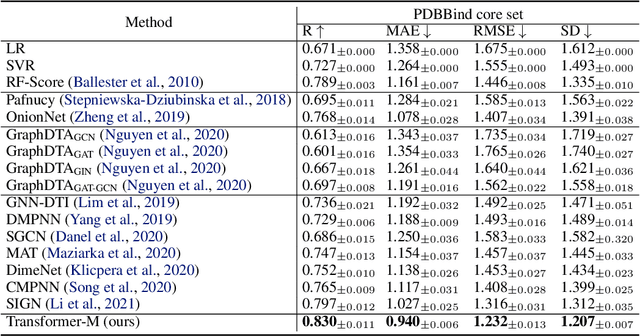
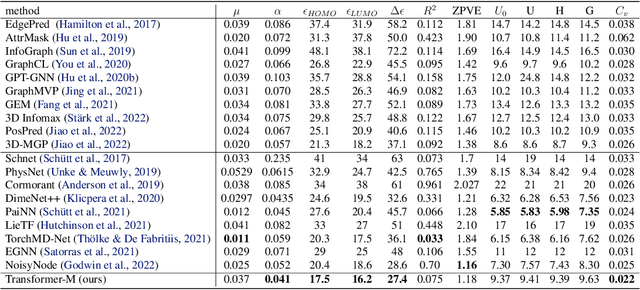
Unlike vision and language data which usually has a unique format, molecules can naturally be characterized using different chemical formulations. One can view a molecule as a 2D graph or define it as a collection of atoms located in a 3D space. For molecular representation learning, most previous works designed neural networks only for a particular data format, making the learned models likely to fail for other data formats. We believe a general-purpose neural network model for chemistry should be able to handle molecular tasks across data modalities. To achieve this goal, in this work, we develop a novel Transformer-based Molecular model called Transformer-M, which can take molecular data of 2D or 3D formats as input and generate meaningful semantic representations. Using the standard Transformer as the backbone architecture, Transformer-M develops two separated channels to encode 2D and 3D structural information and incorporate them with the atom features in the network modules. When the input data is in a particular format, the corresponding channel will be activated, and the other will be disabled. By training on 2D and 3D molecular data with properly designed supervised signals, Transformer-M automatically learns to leverage knowledge from different data modalities and correctly capture the representations. We conducted extensive experiments for Transformer-M. All empirical results show that Transformer-M can simultaneously achieve strong performance on 2D and 3D tasks, suggesting its broad applicability. The code and models will be made publicly available at https://github.com/lsj2408/Transformer-M.